
Ravi Pandya
ravi@iecommerce.com
www.iecommerce.com
+1 425 417 4180
vcard
syndicate this site

ARCHIVES
2007
11
10
2004
10
09
08
07
06
2003
04
02
01
2002
12
11
10
09
08
2001
11
ABOUT ME
Ravi Pandya
Architect
Cloud Computing Futures
Microsoft
ravip at microsoft.com
| 03- | Microsoft |
| 00-02 | Covalent |
| 97-00 | EverythingOffice |
| 96-97 | Jango |
| 93-96 | NetManage |
| 89-93 | Xanadu |
| 88-89 | Hypercube |
| 84,85 | Xerox PARC |
| 83-89 | University of Toronto, Math |
| 86-87 | George Brown College, Dance |
| 95- | Foresight Institute |
| 97- | Institute for Molecular Manufacturing |
DISCLAIMER
The opinions expressed here are purely my own, and do not reflect
the policy of my employer.
Fri 23 Nov 2007
My colleague Eric Northup has mentioned these a few times, and I'm glad I looked them up. The Tornado OS (from my alma mater, U of T) and its successor K42 (at IBM Research) use a fine-grained object-oriented approach to all operating system structures (processes, memory regions, etc.), with built-in clustering for replicated instances across processors. This reduces lock contention and increases cache locality by operating on the per-processor instance as much as possible. Since objects are generally expected to be local, it can optimize for this case, and track cross-processor operations as a special case. There are some policy choices (e.g. maintaining replica tables for all processors) that would probably need to be adapted for manycore.
The scalability architecture is best described in this paper. The memory manager was key, e.g. for locality-aware allocation, padding to cache line size to avoid false sharing, deferring deletion until quiescence to avoid existence locks, etc. An insight as the basic Tornado model was applied to real workloads was that creation-time object specialization isn't sufficient, instead it is better to for example start with an unshared implementation and then upgrade to shared implementation when multiple processes share an object. They were able to improve their 24-proc scalability from "terrible" to pretty good in 2 weeks of work because of good OO discipline and tracing infrastructure.
Overall, I found it striking how the scalability architecture mirrored that for distributed systems - state partitioning, replication, dynamic upgrade, etc. I had expected this from general principles, but it was valuable to see it confirmed in practice with significant workloads. The scalability graphs are impressively linear. Security isn't mentioned, but I expect that the same OO design that gives the OS good modularity and scalability could be applied to give it good capability discipline as well.
12:04 #
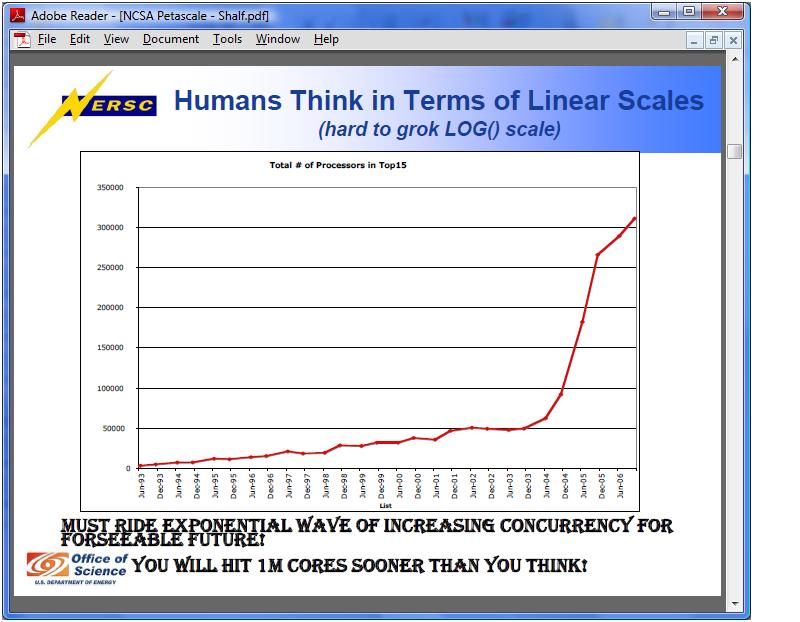
I was looking through the slides from the
NCSA Petascale BOF session at SC07. The slides weren't a
particularly good substitute for the actual presentation,
unfortunately. However, this graph caught my eye - in case you were
wondering whether we'd hit the single-processor scaling wall, it
leaves little room for doubt:
11:51 #
Fri 09 Nov 2007
I've been reading about the L4 microkernel architecture, which is pretty impressive. In this paper they describe how L4Linux can get within 5% of the speed of native Linux, compared with a ~50% performance penality for MkLinux which uses Mach. This comes from a very strong emphasis on performance in the architecture & implementation. They use segment registers instead of page tables for isolation of small processes, which reduces the cost of a context switch between tightly coupled system services. They have also highly optimzed the IPC path with register parameters and a simple transition so it's comparable to a virtual IPI (protected control transfer). It also looks like the architecture is abstract enough to be portable yet still efficient - L4/Alpha also seems to be quite performant.
They are now working on a practical, verified kernel. I really like the approach - instead of using a special implementation language (e.g. Osker in Haskell), or trying to formally specify a complex language like C++, they write the specification in a formalizable subset of Haskell. The specification is actually executable and testable, as well as being formally verifiable, but it does not need to be efficient. The actual kernel is written in a mildly restricted subset of C for which they can define formal semantics, and then they can verify that the C implementation matches the specification in Haskell. This really neat - I've used the approach of writing a model system in advance of the final implementation in the past, but this takes it a to another level, maintaining the model along with the implementation and using it as a cross-check and documentation. I could see this being valuable even in less formal contexts where the design and implementation are complex - an interesting twist on the code is the design. It's also a novel application of the principle that verifying a proof is much easier than generating it.
And to top it all off, it's really, really small. The entire 486 microkernel is 12k bytesof code. 12k bytes.
05:52 #
© 2002-2004 Ravi Pandya | All Rights Reserved